In engineering, redundancy is the duplication of critical components or functions of a system with the intention of increasing reliability of the system, usually in the case of a backup or fail-safe.
In many safety-critical systems, such as fly-by-wire and hydraulic systems in aircraft, some parts of the control system may be triplicated, which is formally termed triple modular redundancy (TMR). An error in one component may then be out-voted by the other two. In a triply redundant system, the system has three sub components, all three of which must fail before the system fails. Since each one rarely fails, and the sub components are expected to fail independently, the probability of all three failing is calculated to be extremely small; often outweighed by other risk factors, e.g., human error. Redundancy may also be known by the terms "majority voting systems", or "voting logic".
Forms of redundancy
There are four major forms of redundancy, these are:
- Hardware redundancy, such as DMR and TMR
- Information redundancy, such as Error detection and correction methods
- Time redundancy, including transient fault detection methods such as Alternate Logic
- Software redundancy such as N-version programming
A modified form of software redundancy, applied to hardware may be:
- Distinct functional redundancy, such as both mechanical and hydraulic braking in a car. Applied in the case of software, code written independently and distinctly different but producing the same results for the same inputs.
DMR:A machine which is Dual Modular Redundant has duplicated elements which work in parallel to provide one form of redundancy. A typical example is a complex computer system which has duplicated nodes, so that should one node fail, another is ready to carry on its work. For instance: the Submarine Command System SMCS used on submarines of the Royal Navy employs duplicated central computing nodes, interconnected by a duplicated LAN.
A lockstep fault-tolerant machine uses replicated elements operating in parallel. At any time, all the replications of each element should be in the same state. The same inputs are provided to each replication, and the same outputs are expected. The outputs of the replications are compared using a voting circuit. A machine with two replications of each element is termed dual modular redundant (DMR). The voting circuit can then only detect a mismatch and recovery relies on other methods. Examples include 1ESS switch. A machine with three replications of each element is termed triple modular redundant (TMR). The voting circuit can determine which replication is in error when a two-to-one vote is observed. In this case, the voting circuit can output the correct result, and discard the erroneous version. After this, the internal state of the erroneous replication is assumed to be different from that of the other two, and the voting circuit can switch to a DMR mode. This model can be applied to any larger number of replications.
TMR: In computing, triple modular redundancy, sometimes called triple-mode redundancy,[1] (TMR) is a fault-tolerant form of N-modular redundancy, in which three systems perform a process and that result is processed by a voting system to produce a single output. If any one of the three systems fails, the other two systems can correct and mask the fault. If the voter fails then the complete system will fail. However, in a good TMR system the voter is much more reliable than the other TMR components. Alternatively, if there is another stage of TMR logic following the current one (for example, in systems such as the Saturn Launch Vehicle Digital Computer), then three voters are used – one for each copy of the next stage of logic.
The TMR concept can be applied to many forms of redundancy, such as software redundancy in the form of N-version programming.
Some ECC memory uses triple modular redundancy hardware (rather than the more common Hamming code), because triple modular redundancy hardware is faster than Hamming error correction hardware.[2] Space satellite systems often use TMR,[3] [4][5] although satellite RAM usually uses Hamming error correction.[6]
To utilize triple modular redundancy, a ship must have at least three chronometers. At one time, the cost of three sufficiently accurate chronometers was more than the cost of a smaller merchant vessel.[7] Some vessels carried more than three chronometers – for example, the HMS Beagle carried 22 chronometers.[8] Some communication systems use N-modular redundancy as a simple form offorward error correction. For example, 5-modular redundancy communication systems (such as FlexRay) use the majority of 5 samples – if any 2 of the 5 results are erroneous, the other 3 results can correct and mask the fault.
N-version programming (NVP), also known as multiversion programming, is a method or process in software engineering where multiple functionally equivalent programs are independently generated from the same initial specifications.[1] The concept of N-version programming was introduced in 1977 by Liming Chen and Algirdas Avizienis with the central conjecture that the "independence of programming efforts will greatly reduce the probability of identical software faults occurring in two or more versions of the program".[1][2]The aim of NVP is to improve the reliability of software operation by building in fault tolerance or redundancy.[1]
[edit]Function of redundancy
The two functions of redundancy are passive redundancy and active redundancy. Both functions prevent performance decline from exceeding specification limits without human intervention using extra capacity.
Passive redundancy uses excess capacity to reduce the impact of component failures. One common form of passive redundancy is the extra strength of cabling and struts used in bridges. This extra strength allows some structural components to fail without bridge collapse. The extra strength used in the design is called the margin of safety.
Eyes and ears provide working examples of passive redundancy. Vision loss in one eye does not cause blindness but depth perception is impaired. Hearing loss in one ear does not cause deafness but directionality is impaired. Performance decline is commonly associated with passive redundancy when a limited number of failures occur.
Active redundancy eliminates performance decline by monitoring performance of individual device, and this monitoring is used in voting logic. The voting logic is linked to switching that automatically reconfigures components. Error detection and correction and the Global Positioning System (GPS) are two examples of active redundancy.
Electrical power distribution provides an example of active redundancy. Several power lines connect each generation facility with customers. Each power line includes monitors that detect overload. Each power line also includes circuit breakers. The combination of power lines provides excess capacity. Circuit breakers disconnect a power line when monitors detect an overload. Power is redistributed across the remaining lines.
[edit]Voting logic
Voting logic uses performance monitoring to determine how to reconfigure individual components so that operation continues without violating specification limitations of the overall system. Voting logic often involves computers, but systems composed of items other than computers may be reconfigured using voting logic. Circuit breakers are an example of a form of non-computer voting logic.
Electrical power systems use power scheduling to reconfigure active redundancy. Computing systems adjust the production output of each generating facility when other generating facilities are suddenly lost. This prevents blackout conditions during major events like earthquake.
The simplest voting logic in computing systems involves two components: primary and alternate. They both run similar software, but the output from the alternate remains inactive during normal operation. The primary monitors itself and periodically sends an activity message to the alternate as long as everything is OK. All outputs from the primary stop, including the activity message, when the primary detects a fault. The alternate activates its output and takes over from the primary after a brief delay when the activity message ceases. Errors in voting logic can cause both to have all outputs active at the same time, can cause both to have all outputs inactive at the same time, or outputs can flutter on and off.
A more reliable form of voting logic involves an odd number of 3 devices or more. All perform identical functions and the outputs are compared by the voting logic. The voting logic establishes a majority when there is a disagreement, and the majority will act to deactivate the output from other device(s) that disagree. A single fault will not interrupt normal operation. This technique is used with avionics systems, such as those responsible for operation of the space shuttle.
[edit]Calculating the probability of system failure
Each duplicate component added to the system decreases the probability of system failure according to the formula:

where:
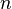 - number of components
- number of components - probability of component i failing
- probability of component i failing - the probability of all components failing (system failure)
- the probability of all components failing (system failure)
This formula assumes independence of failure events. That means that the probability of a component B failing given that a component A has already failed is the same as that of B failing when A has not failed. There are situations where this is unreasonable, such as using two power supplies connected to the same socket, whereby if one socket failed, the other would too.
It also assumes that at only one component is needed to keep the system running. If 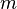 components are needed for the system to survive, out of , the probability of failure is[citation needed]
components are needed for the system to survive, out of , the probability of failure is[citation needed]
components are needed for the system to survive, out of , the probability of failure is[citation needed]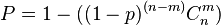 , Assuming all components have equal probability, , of failure
, Assuming all components have equal probability, , of failure
This model is probably unrealistic in that it assumes that components are not replaced in time when they fail.